What you get when you think of Postgres storage as a transaction journal
Neon views databases as a sum of transactions, prioritizing the development workflow over mere data storage

There are two ways to think about a relational database.
The first is data-centric. Data is organized into tables with rows and columns, each representing a specific entity or concept. In this mental model of a database, the primary focus is on storing and retrieving data. This makes a lot of sense.
But we could imagine a second way to think about databases: transaction-centric. From this point of view, the database is seen as a dynamic journal of transactions. Each event would represent a specific operation, such as creating, updating, or deleting data. The database storage would then be conceptualized as an event timeline instead of a static representation of the data.
The data-centric database model has given us excellent software for storing data in a robust and reliable way. But, is this model also limiting us? Databases have struggled to keep up with the modern development experience, which is much more about building with data than simply storing and retrieving it.
When we started Neon, we were very interested in exploring what would happen if we applied a transaction-centric paradigm to Postgres. If we could re-architect the Postgres internals so the storage is conceptualized as a transaction journal versus a static entity, could this enable developers to modify their data much more agilely and safely, e.g., by allowing branching data, queries that go back in time, or immediate restores from a previous state?
We realized Postgres already had a mechanism that could enable this: WAL (Write-Ahead Log).
Rearchitecting Postgres storage as transaction-centric
The essential building block: Postgres WAL
The Write-Ahead Log (WAL) is a fundamental component of Postgres. It logs all transactions and database modifications before applying them to the primary data files. This allows Postgres to restore the database in case the server or service is interrupted.
Here’s an example of how WAL works. Let’s say we have a simple users table:
CREATE TABLE users (
id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
name VARCHAR(255),
email VARCHAR(255)
);Now, let’s insert a new user:
INSERT INTO users (name, email) VALUES ('John Doe', 'john@example.com');Before this change is written to the users table on disk, Postgres will write a log entry to the WAL. The WAL is organized into segment files. Each segment file is typically 16MB by default, although this can be configured.
The segment file naming convention conveys specific information about the file’s position in the sequence of logs. Here, we’ve created a new database and table, so our file is 000000010000000000001.
Let’s break this down:
00000001: This is the timeline ID. Postgres uses timelines to manage different forks of the database history, which typically come into play during recovery, or when a standby becomes a master. The timeline increases when a new timeline is created during a failover or when creating a new standby server from a backup.000000: This is the first part of the log sequence number, often called the “segment number” or “logid”. It represents the major division of the log sequence and is incremented each time 4GB of WAL is filled.00000001: This is the second part of the log sequence number, referred to as the “offset’ or “logset” It indicates the specific segment within the log sequence and is incremented each time 16MB of WAL is filled.
So, the filename 000000010000000000000001 indicates a timeline ID of 1, a Log Sequence Number (LSN) of 0x00000000, and a segment Number of 1. This means that the amount of bytes written in the WAL since the database start, as represented by this filename, is (segment_num * 4GB) + (offset * 16MB), where the segment_num is 1 and the offset is 0. The following file would be 000000010000000000000002.
If we were to open this, what would the file look like? Well, the WAL log is in binary format for the DBMS to read rather than the prying eyes of humans, but we can use pg_waldump to create a human-readable format.
We can run:
pg_waldump 000000010000000000000001 This will output thousands of rows showing what the database has been up to. Let’s pick a few rows which deal with our above INSERT:
rmgr: Transaction len (rec/tot): 48/48, tx: 1000, lsn: 0/03000020, prev 0/03000000, desc: BEGINThis is the beginning of the transaction. The rmgr indicates that the Resource Manager manages a transaction-related record for this entry. We then have a length (len), a transaction ID (tx), and a Log Sequence Number (lsn), followed by the description (desc).
The following line captures the record of an INSERT operation into the Heap:
rmgr: Heap len (rec/tot): 150/218, tx: 1000, lsn: 0/03000040, prev 0/03000020, desc: INSERT, blkref #0: rel 1664/0/2600 blk 5Again, this has the length, transaction ID, and LSN. But this entry also includes the block reference (blkref #0), which states that this operation affects the first block reference of the relation with an identifier (rel 1664/0/2600) on block 5. This details precisely where the insertion took place in the file system.
The following line describes an INSERT_LEAF operation on a B-tree index:
rmgr: Btree len (rec/tot): 85/155, tx: 1000, lsn: 0/03000080, prev 0/03000060, desc: INSERT_LEAF, blkref #0: rel 1664/0/2602 blk 4This maintains our index for efficient data retrieval.
Finally, we have the COMMIT marking the successful completion of the transaction, finalized at a precise timestamp 2024-04-20 10:00:00.123456 EST:
rmgr: Transaction len (rec/tot): 48/48, tx: 1000, lsn: 0/030000A0, prev 0/03000080, desc: COMMIT 2024-04-20 10:00:00.123456 ESTThis entry indicates that all operations within the transaction are complete and have been durably recorded. If the database were to crash after the WAL entry was written but before the change was applied to the users table, Postgres will use the WAL to “replay” the transaction and ensure that the change is not lost.
This example illustrates the key idea: by logging every change in the WAL before it’s applied to the actual data files, Postgres ensures data integrity and enables features like point-in-time recovery.
Bringing WAL front and center
The WAL in Postgres was originally designed to ensure atomicity and durability of transactions, yet it also has the potential to enable a broader range of functionalities.
If we wanted to re-architect Postgres as a transaction-centric database, WAL becomes the source of truth, the source of history for the entire database. Neon builds on this principle. Differently than in conventional Postgres systems, Neon de-couples storage and computation and uses WAL as the core component of the database’s storage system.
Let’s illustrate what this means with a comparison: in conventional Postgres settings (e.g. think RDS),
- Each database instance manages its attached block storage (EBS).
- Compute instances are tightly coupled with storage.
- A WAL record is kept for ensuring data consistency and recovery.
In Neon,
- WAL is conceptualized as the core of the storage mechanism.
- All changes are first recorded in WAL, which is then processed to update the database state.
- WAL is streamed to a layered storage system where data is organized into immutable files in object storage.
- Compute nodes are ephemeral and stateless.
Neon relies on WAL to separate storage and compute through two different components: Safekeepers and Pageservers. Safekeepers ensure the durability of database changes; Postgres streams the WAL to the Safekeepers, where a Paxos-like consensus algorithm ensures that transactions can be restored if lost (the core function of the WAL). Pageservers read the WAL from the Safekeepers to find the modified pages, convert them into Neon Pages, and process them into S3 object storage.
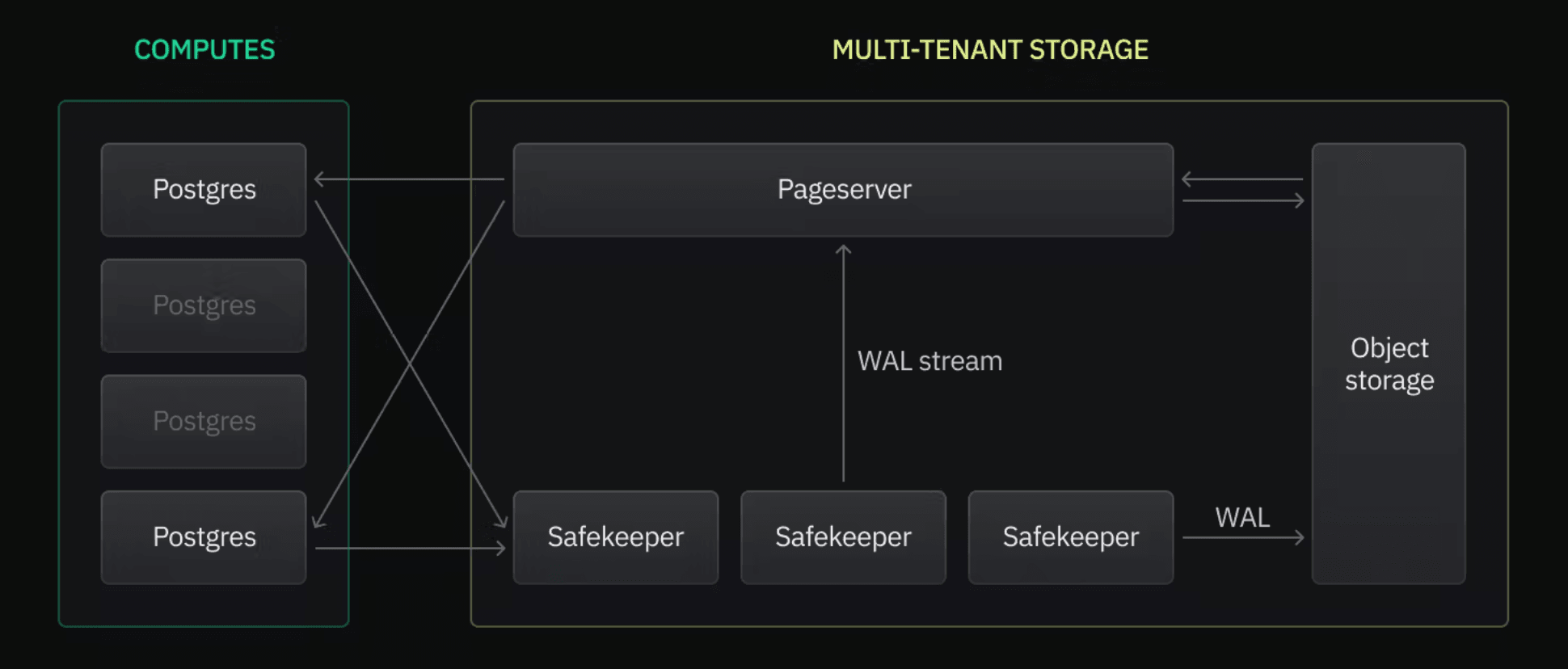
What this enables
By reimagining the use of WAL, Neon can add new features to Postgres that improve the development experience. A few examples (but we’re only starting to tap into the possibilities of this technology):
Database branching with data and schema
Neon enables database branching via copy-on-write. This allows developers to create and manage separate branches of the database for development, testing, or staging without duplicating the entire database, similar to how branches are used in version control systems.
The core element of the log we use for branching is the LSN, the log sequence number. As we’ve seen above, every single entry to the log has a unique identifier that allows for precise synchronization and replication. When you create a branch in Neon, you’re essentially creating a new pointer to a specific LSN in the WAL. This means that the branch starts with the exact same data as the parent branch at that point in time.
Thanks to the copy-on-write mechanism, any changes made to the branch are isolated from the parent branch. When you write to the branch, Neon creates new pages (or new versions of pages) specifically for the branch, leaving the original pages untouched.
This is why creating a branch is fast and doesn’t impact the performance of the parent branch. You’re not actually copying all the data; you’re just creating a new pointer in the WAL.
Instant PITR
This storage architecture also allows for quick point-in-time recoveries, enabling databases to be restored to any previous state defined by a LSN. This is made possible because the entire database state is continuously recorded in WAL, stored, and indexed in a way that makes historical data rapidly accessible.
Under the hood, instant recovery is a specialized form of branching. When you initiate a point-in-time recovery, Neon creates a new branch pointing to the specific LSN in the WAL corresponding to your chosen point in time. When you perform a Point-in-Time Restore, you restore to a particular LSN. The Pageserver retains all the WAL in a randomly-accessible format, so it can reconstruct pages as of any LSN, allowing for time travel queries.
Ephemeral read replicas
Another consequence of this custom storage are ephemeral, instant read replicas. Neon’s read replicas are independent read-only compute instances designed to perform read operations on the same data as the read-write primary. However, unlike traditional read replicas, Neon’s instant replicas do not actually replicate data across database instances.
Instead, both the read-write primary and the read-only replicas send read requests to the same Neon Pageserver, which serves as the single source of truth for the data. This is made possible by Neon’s unique architecture that separates storage and compute.
When the read-write primary makes updates, the Safekeepers durably store the data changes until the Pageservers process them. At the same time, the Safekeepers keep the read-only replicas up to date with the latest changes to maintain data consistency.
Time travel queries
Neon’s time travel queries leverage the LSN to enable querying the database at any previous state. Each transaction recorded in the WAL is associated with an LSN, which uniquely identifies every change. When a time travel query is executed, Neon’s Pageservers use the specified LSN to retrieve and reconstruct the database’s state at that particular moment.This functionality is useful for auditing and debugging, allowing developers to examine database states before and after specific changes, and comparing historical data against current data. It’s also useful for double-checking the right timestamp before a PITR.
A new way to build with Postgres
The choice to design Neon’s architecture around Postgres WAL has allowed us to rethink how databases work. For the end user, the effect is transparent: from the transactions point of view, a Neon database looks like any other Postgres database. But under the hood, our unique approach to storage opens the door to a new database experience. Give Neon a go if you haven’t already.



